Laboratorio 2 |
Comunicación de datos
Protocolos TCP/IP
Introducción
En
este laboratorio vamos a afianzar los conocimientos sobre cómo funciona la pila
de protocolos TCP/IP, que nos permiten las comunicaciones a través de Internet.
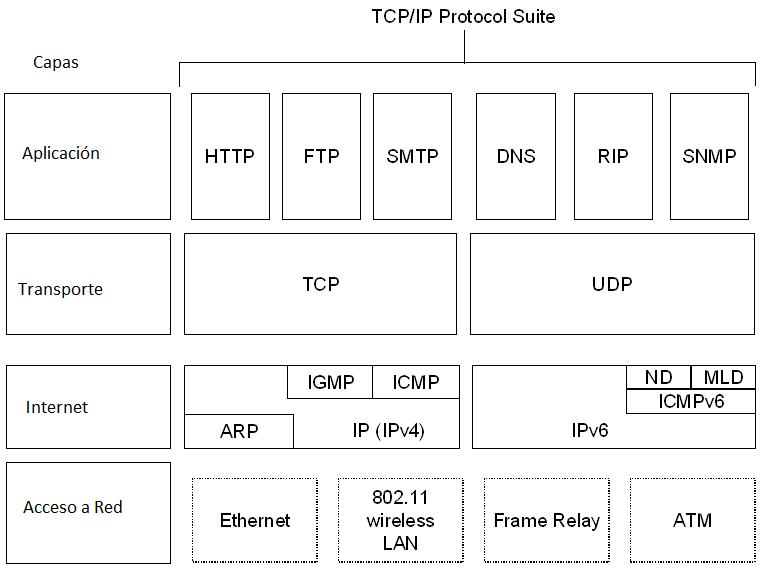
La pila TCP/IP recibe su nombre de los protocolos TCP (Transmission Control
Protocol) e IP (Internet Protocol), pero involucra a muchos más protocolos, que
generalmente se representan, y se pueden entender, como una pila formada por
diversas capas.
La
primera columna representa los cuatro niveles de la pila TCP/IP (capa de
aplicación, capa de transporte, capa de Internet y capa física o de red). La
segunda columna, enumera (algunos de) los protocolos que podemos encontrar en
cada una de las capas (por ejemplo, http y ftp en la capa de aplicación, donde
también se encuentran pop o imap, tcp y udp en la capa de transporte, IPv4,
IPv6 o ARP en la capa de Internet, Ethernet y algunos otros en la capa física).
Objetivos:
Ø Ilustrar
cómo funcionan algunos de los protocolos de cada capa.
Ø Conocer
las diferencias entre el papel que juegan las distintas capas.
Ø Realizar algunos ejercicios con los
protocolos de la capa de aplicación.
Procedimiento:
En
particular, en la práctica de hoy, prestaremos atención a la capa de aplicación
y algunos de sus protocolos.
1.
En primer lugar, vamos a ver cómo podemos acceder a recursos que están
disponibles a través de Internet, conociendo tanto el protocolo por el que
están accesibles como su ruta.
1.1
Abre 7 pestañas del navegador Mozilla Firefox y copia en cada una de ellas las
siguientes rutas:
C:
www.uca.edu.sv/investigacion/tutoriales/tcp-ip.html
http://www.uca.edu.sv/investigacion/tutoriales/tcp-ip.html
www.uca.edu.sv/investigacion/tutoriales/tcp-ip2.gif
ftp.epson.com/laser/ACTLQA.TXT
ftp://ftp.epson.com/laser/ACTLQA.TXT
ftp://ftp.epson.com/laser/LASERIJ.GIF
¿A
qué tipo de recursos (tipos de archivo) has podido acceder por medio de tu
navegador?
R. Se pudo
acceder a páginas web y a descargas de archivos por FTP.
¿Qué
protocolos de aplicación es capaz de reconocer?
R. Se
reconocen protocolos http y ftp.
¿Qué
protocolos ha sido capaz de inferir incluso sin nuestra ayuda (sin consignar
nosotros el nombre del protocolo)?
R. Sin
necesidad especificarlo se ha podido inferir http.
1.2
Abrimos ahora Paint. Trata de acceder (Archivo -> Abrir) a las siguientes
direcciones:
http://www.uca.edu.sv/investigacion/tutoriales/tcp-ip.html
http://www.uca.edu.sv/investigacion/tutoriales/tcp-ip2.gif
ftp://ftp.epson.com/laser/ACTLQA.TXT
ftp://ftp.epson.com/laser/LASERIJ.GIF
¿Qué
formatos de archivo reconoce Paint?
R. Paint
es capaz de reconocer archivos con formato “.gif”.
¿Es
capaz Paint de trabajar con recursos a través de su dirección web?
R. Paint
es capaz de trabajar con recursos a través de una dirección web siempre y
cuando este en un formato valido para esta aplicación.
1.3
Repetir la misma prueba con el bloc de notas. Trata de acceder a las siguientes
direcciones:
http://www.uca.edu.sv/investigacion/tutoriales/tcp-ip.html
http://www.uca.edu.sv/investigacion/tutoriales/tcp-ip2.gif
¿Qué
formatos de archivo reconoce notepad?
R. Notepad
es capaz de reconocer archivos con formato “.html” mas no “.gif”.
¿Es
capaz notepad de trabajar con recursos a través de su dirección web?
R. En
efecto Notepad es capaz de trabajar con recursos desde la web.
1.4
Finalmente ejecuta Filezilla, y trata de acceder a las siguientes direcciones
(copia también la parte correspondiente al protocolo “http://” o “ftp://”):
http://www.uca.edu.sv/investigacion/tutoriales/tcp-ip.html
ftp://ftp.epson.com/laser/ACTLQA.TXT
Comenta
lo que ha sucedido en cada uno de los dos casos.
R. En el
primer caso se ha desplegado en la pantalla del buscador una página web. En el
segundo caso se ha presentado una pantalla de solitud de credenciales para el
acceso a una descarga de ficheros.
2.
Vamos a tratar de entender ahora un poco mejor cómo son las direcciones que nos
permiten acceder a recursos a través de Internet. Estas direcciones se conocen
como URL’s (Uniform Resource Locator) o URI’s (Uniform Resource Identifier), y
ya las hemos utilizado, por ejemplo, para definir los enlaces a páginas web en
HTML.
Observa
por ejemplo el siguiente enlace:
http://es.wikipedia.org/w/wiki.phtml?title=URL&action=history
Accede
a la página señalada. Generalmente las url’s responden al siguiente esquema:
protocolo://máquina.dominio:puerto/camino/fichero?parámetros
El
protocolo puede ser alguno entre http (protocolo de transferencia de
hipertexto), https (protocolo seguro de transferencia de hipertexto), ftp
(protocolo de transferencia de ficheros), smtp (protocolo simple de
transferencia de correo), pop (protocolo de la oficina de correo), ldap
(protocolo ligero de acceso a directorios), file (para archivos disponibles en
la máquina local), telnet, etc … La máquina y el dominio conforman la parte más
identificable de una url. Por ejemplo, en https://belenus.unirioja.es, belenus
es un servidor (o un subdominio) dentro del dominio “unirioja.es”. Los puertos
están relacionados con el protocolo TCP. El camino especifica la ruta del
recurso solicitado en su servidor. El fichero es el recurso solicitado, y la
lista de parámetros nos permiten enviarle información modificando así su
respuesta.
Identifica
cada una de esas partes en la url
http://es.wikipedia.org/w/wiki.phtml?title=URL&action=history.
Toma
la dirección anterior de la wikipedia http://es.wikipedia.org/w/wiki.phtml?title=URL&action=history
y en la barra del navegador realiza las siguientes modificaciones. Explica en
el informe (blog) el resultado (después de cada modificación recupera la url
original):
-
Modifica el protocolo “http” por “https” y recarga la página.
-
Cambia “es” por “ES” y recarga la página.
-
Cambia “wikipedia” por “WIKIPEDIA” y recarga la página.
-
Cambia “es.wikipedia.org” por “es.wikipedia.org:80” y recarga la página.
-
Cambia “es.wikipedia.org” por “es.wikipedia.org:81” y recarga la página (¿cuál
es el puerto por defecto del protocolo http?).
-
Cambia “/w/” por “/W/” y recarga la página.
-
Cambia “URL” por “Logroño” y recarga la página.
-
Cambia “history” por “History” y recarga la página.
3.
La información a través de Internet se comunica por medio de paquetes.
Igual
que se dice que en un disco duro la unidad mínima de memoria es un sector, y en
un sistema de archivos la unidad mínima de memoria era un clúster, en Internet
dicha unidad recibe el nombre de paquete. Cada vez que hacemos una solicitud de
un recurso en Internet, estamos generando uno o varios paquetes que contienen
la misma (y que serán encaminados a su destino por un “router”). La respuesta
que recibamos también estará formada por paquetes que nuestro programa cliente
(dependiente del protocolo que usemos, ftp, http, pop, smtp…) convertirá en una
página web, un mensaje de correo, una imagen o un fichero.
Los
paquetes se construyen de la siguiente forma. A una petición que hagamos en el
navegador, o a su respuesta desde el servidor, se le asignará en primer lugar
una “cabecera de aplicación”. La misma contendrá información referente al
protocolo usado (de los de la capa de aplicación), al método en que se ha
solicitado el recurso (GET, POST…), al agente de usuario (Mozilla…), a la
máquina huésped del recurso…

Las
restantes capas añaden información referente a puertos, IPs, direcciones
ETHERNET….
No hay comentarios.:
Publicar un comentario